プログラム=データ=遺伝子? Lispは無慈悲な言語の女王
(Lisp Advent Calendar 2013 18日目の記事)
しばしばLispの特徴として「プログラムを生成するプログラムを書ける」ということが言われるわけだが、普通の人はこれを聞いてどう解釈したらよいものか悩むと思う。字面通りに受け取ると、あたかも勝手に世の中の問題を把握してそれを解決するプログラムを出力してくれる真の人工知能のようなものを想像してしまうかもしれない。しかし残念ながら、そうした所謂「強いAI」は人工知能研究における聖杯であり、いまだにSFの範疇から出るものではない。
LISPerの言う「プログラムを生成するプログラム」とは普通もっと限定された意味である。そしてそれはほとんどの場合マクロによって実現される。
evalとマクロ
Lispではプログラムとデータが同じ形をしているので、それまでプログラムとして扱っていたものを突如データとみなして操作することができる。逆に、データとして操作したコードはevalを使えば今度はプログラムとして評価されることになる。例えば、変数にnilを代入するnilfを二つの方法で定義してみる。
(defun nilf-1 (x) (eval (list 'setf x nil))) (defmacro nilf-2 (x) `(setf ,x nil)) (defparameter x 10) (nilf-1 'x) ;; x => nil (defparameter x 10) (nilf-2 x) ;; x => nil
nilf-1は関数の中でLispプログラムを組立て、それをevalで評価することによって関数の外の変数への代入を実現している。しかしnilf-1は関数であるため引数が評価されないようにクォートを付けて呼び出す必要がある。一方でマクロとして定義したnilf-2はクォートがいらない。
なぜこのような違いが生まれるのだろうか。それは評価されるタイミングが違うからである。
Common Lispではプログラムは読み込み時、コンパイル時、実行時の3つの段階を経て実行される。Lispプログラムを読み込むタイミングで展開されるのがクォートなどのリーダーマクロであり、コンパイル前に展開されるのが通常のマクロ、そして関数は実行時に評価される。ひとたびコンパイルされてしまえばそのプログラムを何回実行してもマクロ展開のオーバーヘッドは残らない。逆に、evalを使うやり方では実行時にその都度evalの評価対象のプログラムが組み立てられコンパイルされるため、効率上のデメリットがある。そのためevalはREPLを除けば普段はあまり目にすることはない。実際Clojurescriptのようにevalが封印されているものすらある。
ではevalを活用できる場面はないのかといえば、もちろんある。プログラムの実行時に新しいプログラムを生成するプログラムを書く必要があるときがそうだ。そのようなものとしては、例えば遺伝的プログラミングがある。
遺伝的プログラミングとは
遺伝的プログラミング(以下GP)とは遺伝的アルゴリズム(以下GA)の拡張の一つで、GAではビット列で遺伝子を表現するところを、GPでは木構造で遺伝子を表現するところが異なる。
ところでLispプログラムはS式で表現されているわけだが、S式は構文木そのものであるので、LispプログラムはそのままGPの遺伝子と見ることができる。この遺伝子=Lispプログラムの集団を交配によって徐々に変化させながら、各世代で生成されるLispプログラムを評価し、優良な個体を優先的に次世代に残すサイクルを繰り返すのがGPのアルゴリズムとなる。
交配の方法は色々あるが、代表的なものとしては突然変異(mutation)や交叉(crossover)がある。突然変異では一つの個体のノードが別のものに変わって新しい個体が生まれる。交叉では二つの個体が部分木を交換し、新しい個体が二つ生まれる。

ただし、交配の対象となる個体の選択や、これらの交配のための操作は確率的に行なわれるため、その確率を制御するためのメタパラメータを適当に設定してやる必要がある。
GPをLispで実装するのは他言語に比べれば非常に易しい。交配に伴なう操作は単なるリスト処理であり、個体であるLispプログラムを実行するには単にevalしてやればいいのだ。実際、遺伝的プログラミングの草分けとして知られるJohn R. Kozaの教科書のサンプルコードもCommon Lispで書かれている。
Kozaのプログラムの紹介
Kozaによるサンプルコードが以下のURLにあるのでダウンロードしてloadする。
http://faculty.hampshire.edu/lspector/courses/koza-gp.lisp
20年前のコードだが、CLtL2で書かれているので、後方互換性のあるANSI Common Lispに準拠した処理系ならそのまま動くはずだ(SBCL 1.1.7 on Linuxで動作確認済)。
(load "koza-gp.lisp")
今回は最も単純な例として回帰問題を扱う。まずデータセットを用意するところから始めよう。
(require :alexandria) ; 正規分布のサンプリングに使う ;; 近似対象の関数 (defun target-func (x) (* (- x 1) x (+ x 1))) (defparameter x-samples (loop repeat 100 collect (1- (random 2d0)))) (defparameter y-samples (mapcar (lambda (x) (+ (target-func x) (* (alexandria:gaussian-random) 0.1d0))) x-samples)) (defun define-fitness-cases () (mapcar #'list x-samples y-samples))
これで三次曲線(* (- x 1) x (+ x 1))の周りに分布するサンプル点が100個できる。このサンプル点の集合から元の関数を復元するのがこの問題の目的となる。
次に、個体=生成されるプログラムの素材として、どのような関数(非終端記号)や終端記号が使えるかを指定する必要がある。関数には任意のLisp関数が使えるが、引数の型チェックなどはしないようだ。今回は関数は四則演算のみ、終端記号としてはシンボルxとランダムの整数のみが使えるとする。
(defun define-terminal-set () (values '(x :integer-random-constant))) ;;; ゼロ除算でエラーを出さないように (defun % (numerator denominator) (if (= 0 denominator) 1 (/ numerator denominator))) (defun define-function-set () (values '(+ - * %) ; 候補の関数のリスト '(2 2 2 2))) ; それぞれの関数の引数の数
次にいよいよ評価関数を定義する。
評価関数は個体であるプログラムと、 define-fitness-cases で定義されるデータセットを受け取り、個体の評価値を返す。評価値は小さいほど良い。 program は (* (- x 1) x (+ x 1)) のようなリストなので、データセットのサンプル点の値をxに束縛して (eval program) することで予測値が出る。予測値と実際の値との平均二乗誤差(RMSE)を取って、これを評価値とする。
ついでに生成されるプログラムが巨大になるのを避けるために、木の深さに対する罰則項を付けておく。 *alpha* は誤差最小化とプログラムサイズ最小化のバランスを取るパラメータだ。
(defparameter *alpha* 0.001d0) (defun evaluate-fitness (program fitness-cases) (let* ((square-error (loop for data in fitness-cases sum (let* ((x (car data)) (y (cadr data)) (err (- (eval program) y))) (* err err)))) (rmse (sqrt (/ square-error (length fitness-cases))))) (+ rmse (* *alpha* (max-depth-of-tree program)))))
あとは諸々のパラメータや、終了条件を適当に設定し、これまで定義してきた関数をまとめて多値で返す問題関数REGRESSIONを定義する。
(defun define-parameters () (setf *max-depth-for-new-individuals* 5) (setf *max-depth-for-individuals-after-crossover* 10) (setf *fitness-proportionate-reproduction-fraction* 0.1) ; 一世代に交換される個体の割合 (setf *crossover-at-any-point-fraction* 0.2) (setf *crossover-at-function-point-fraction* 0.2) (setf *max-depth-for-new-subtrees-in-mutants* 4) (setf *method-of-selection* :fitness-proportionate) (setf *method-of-generation* :ramped-half-and-half) (values)) (defun define-termination-criterion (current-generation maximum-generations best-standardized-fitness best-hits) (declare (ignore best-standardized-fitness best-hits)) (values (>= current-generation maximum-generations))) ; 世代数が上限にいくまで ;;; 問題関数 (defun REGRESSION () (values 'define-function-set ; 関数名のシンボルのリストと各関数の引数の数のリストを返す関数 'define-terminal-set ; 終端記号のリストを返す関数 'define-fitness-cases ; 評価に使うデータセットを定義する関数 'evaluate-fitness ; 評価関数 'define-parameters ; 進化のメタパラメータを定義する関数 'define-termination-criterion)) ; 終了条件
以上で準備は終わりとなる。以下のようにしてシミュレーションを実行する。
(run-genetic-programming-system 'REGRESSION 1.0 ; 乱数のシード 100 ; 最大世代数 2000) ; 集団のサイズ
10分ほど待つと、以下のような結果が出力されていると思う。
Parameters used for this run. ============================= Maximum number of Generations: 100 Size of Population: 2000 Maximum depth of new individuals: 5 Maximum depth of new subtrees for mutants: 4 Maximum depth of individuals after crossover: 10 Fitness-proportionate reproduction fraction: 0.1 Crossover at any point fraction: 0.2 Crossover at function points fraction: 0.2 Number of fitness cases: NIL Selection method: FITNESS-PROPORTIONATE Generation method: RAMPED-HALF-AND-HALF Randomizer seed: 1.0d0 Generation 0: Average standardized-fitness = 682360.0034408907d0. The best individual program of the population had a standardized fitness measure of 0.18029786329188047d0 and NIL hits. It was: (% (- (% X -6) (- X 1)) (+ (* X -4) (% -1 X))) Generation 1: Average standardized-fitness = 30974.97849042459d0. The best individual program of the population had a standardized fitness measure of 0.18029786329188047d0 and NIL hits. It was: (% (- (% X -6) (- X 1)) (+ (* X -4) (% -1 X))) (中略) Generation 99: Average standardized-fitness = 264.06375933445685d0. The best individual program of the population had a standardized fitness measure of 0.14858744727766707d0 and NIL hits. It was: (% (* (* (* (+ -2 X) (+ -2 X)) (* (- -1 X) (% X -8))) (+ (* 8 (% 6 7)) (+ (- X -6) X))) -8) The best-of-run individual program for this run was found on generation 23 and had a standardized fitness measure of 0.11737380905714517d0 and NIL hits. It was: (* X (* X (+ X (% (+ (* (% X (+ -6 -7)) X) (% (- -4 (% X X)) X)) (- 6 1)))))
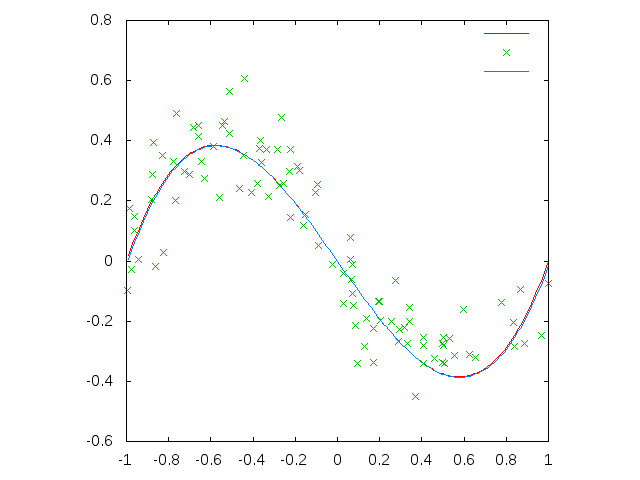
この最良の個体 (* X (* X (+ X (% (+ (* (% X (+ -6 -7)) X) (% (- -4 (% X X)) X)) (- 6 1))))) をプロットしたものが上の図の青線である。
赤線が元々の関数なのでほぼ正確に復元できていると思う。