書籍「オンライン機械学習」を買ったのでCommon Lispで実装してみた。
")
オンライン機械学習を買ったので、書いてあるアルゴリズムから線形識別器をいくつか試してみた。オンライン学習とは、データを一括処理するバッチ学習に対して、個々のデータを逐次処理する学習手法のこと。オンライン学習だと以下のようなうれしいことがある。
- 実装が簡単: 基本的に実装は1ステップ毎の処理を実装するだけでほとんど終わる(スッキリ!)
- リアルタイム処理に組込める: その時点までの観測を元にした学習結果が常に予測に使えるので、学習しながら予測もしなければならない応用に向いている
- 収束が速く、データの性質が徐々に変化しても追従できる: これはリアルタイム処理に対して使うにはいい性質だが、偏ったデータやノイズに弱いという諸刃の剣でもある(そこで最適化対象に正則化項を入れるなどして悪影響を減らそうとする)。
データを一つ一つ処理するので、オンライン学習の計算量はデータ数に対して線形に増加する。バッチ学習のカーネル法などでは、データ数について2~3乗のオーダで計算量が増えていったりして、数万を超える大規模データには使えない。例えば非線形カーネルを使うSVMではかなり速いとされるSMOアルゴリズムでも時間計算量がO(mn^2)だが、線形カーネルに限ればSVMはオンラインに学習することができてO(mn)で済む (m: 入力次元、n: データ数)。
この本で扱っているほとんどの学習手法は線形分離可能を前提とするが、データを高次元化させたりして実用レベルの精度を出せることも多い。例えばTwitterのストリーミングAPIからデータを拾ってきて、単語のあるなしに対応する特徴量を持つ数万次元の疎なベクトルを入力として学習し、リアルタイムに何らかの予測を立てるような応用に適している。この本の後半にはそういった応用に向けて、疎なベクトル向けのベクトル演算の実装の仕方のようなものも解説されている。全体的に実装を指向した本という印象である。
実装言語はCommon Lisp
最近、機械学習界隈で話題に上るのはPythonなどのスクリプト言語が多いが、実際の学習アルゴリズム部分はCなどの高速な言語で実装されたライブラリ中にあって、まとまったデータをライブラリに渡しているだけの場合が多い気がする。まとまったデータを渡すバッチ処理ならそれでもいいかもしれないが、オンライン処理ではこの外部呼び出しのオーバーヘッドが問題となるし、そもそも単純なループ処理が遅いスクリプト言語にはあまり向かないように思える。
上述のようにオンラインで学習しながらその都度予測して何かをやるというアプリケーションを書くには、数値計算のような低水準なものからドメイン特化言語の定義のような高水準なものまでカバーする言語で書きたいのが人情である。というわけでCommon Lispを用いる。
コード
quicklispですぐ読み込める形にしたものをgithubに置いておく。
インストールするには、まずシェルから
$ cd ~/quicklisp/local-projects/ $ git clone https://github.com/masatoi/cl-online-learning.git
次にLisp処理系からquicklispでロードする。
(ql:quickload :cl-online-learning)
ベクトル演算は副作用あり
ベクトル演算はとりあえず密ベクトルに絞って考えて、CLML(Common Lisp Machine Learning)に付いてたユーティリティの一部を流用する。ベクトルはdouble-float型のsimple-arrayで表現する。ベクトル同士の足し算やスカラー倍などの操作において、結果受け取り用のベクトルを渡して、それを破壊的に変更することでベクトル演算の度にmake-arrayさせないようになっている。
(let ((v1 (make-array 3 :element-type 'double-float :initial-contents '(1d0 2d0 3d0))) (v2 (make-array 3 :element-type 'double-float :initial-contents '(10d0 20d0 30d0))) (result (make-array 3 :element-type 'double-float :initial-element 0d0))) (print (v+ v1 v2 result)) (print (v-scale v1 3d0 result)) (print (v+ result v2 result)) (print result)) ; #(11.0d0 22.0d0 33.0d0) ; #(3.0d0 6.0d0 9.0d0) ; #(13.0d0 26.0d0 39.0d0) ; #(13.0d0 26.0d0 39.0d0)
ベクトル演算の返り値は結果受け取り用ベクトルと同一オブジェクトなので、返り値を束縛した後に同じ結果受け取り用ベクトルを使って別のベクトル演算をやると値が変わってハマることになる(ハマった)。
予測とテスト部分
線形識別器なので、重みと入力ベクトルの内積を取って、それが正か負かでクラスを分ける。
;;; 符号関数 (defun sign (x) (if (> x 0d0) 1d0 -1d0)) ;;; 線形識別器の決定境界 (defun f (input weight bias) (+ (inner-product weight input) bias)) ;;; 線形識別器の予測 (defun predict (input weight bias) (sign (f input weight bias)))
どうせシーケンシャルアクセスしかしないので、データセットは教師信号と入力ベクトルのドット対のリストということにする。するとテストはこう書ける。
(defun test (test-data weight bias) (let ((len (length test-data)) (n-correct (count-if (lambda (datum) (= (predict (cdr datum) weight bias) (car datum))) test-data))) (format t "Accuracy: ~f%, Correct: ~A, Total: ~A~%" (* (/ n-correct len) 100.0) n-correct len)))
訓練部分
とりあえず最も基本となるパーセプトロンと、線形SVMを確率的勾配法で更新する場合を実装してみる。
バイアス(決定境界fの切片)は、入力ベクトルの次元を1つ上げて(常に値が定数となる要素を入力ベクトルに追加する)、普通に重みを学習すると、重みベクトルの余計に1次元増えた要素がバイアスになっている。だが、この本によるとバイアスの更新は他の重みとは分けた方がいいとある。バイアスだけ学習率を変えるなどのヒューリスティクスがあるらしい。
;;; 3.3 パーセプトロン (アルゴリズム3.1) ;; 次のステップのweightとbiasを返す。なおweightは破壊的に変更される。 (defun train-perceptron-1step (input weight bias training-label) (if (<= (* training-label (f input weight bias)) 0d0) (if (> training-label 0d0) (values (v+ weight input weight) (+ bias 1d0)) (values (v- weight input weight) (- bias 1d0))) (values weight bias))) (defun train-perceptron-all (training-data weight bias) (loop for datum in training-data do (setf bias (nth-value 1 (train-perceptron-1step (cdr datum) weight bias (car datum))))) (values weight bias)) (defun train-perceptron (training-data) (let ((weight (make-dvec (length (cdar training-data)) 0d0)) (bias 0d0)) (train-perceptron-all training-data weight bias))) ;;; 3.6 サポートベクトルマシン (アルゴリズム3.3) 線形SVM + 確率的勾配法(SGD) (defun train-svm-sgd-1step (input weight bias learning-rate regularization-parameter training-label v-scale-result) (let* ((update-p (<= (* training-label (f input weight bias)) 1d0)) (tmp-weight (if update-p (v+ weight (v-scale input (* learning-rate training-label) v-scale-result) weight) weight)) (tmp-bias (if update-p (+ bias (* learning-rate training-label)) bias))) (values (v-scale tmp-weight (- 1d0 (* 2d0 learning-rate regularization-parameter)) weight) (* tmp-bias (- 1d0 (* 2d0 learning-rate regularization-parameter)))))) (defun train-svm-sgd-all (training-data weight bias learning-rate regularization-parameter v-scale-result) (loop for datum in training-data do (setf bias (nth-value 1 (train-svm-sgd-1step (cdr datum) weight bias learning-rate regularization-parameter (car datum) v-scale-result)))) (values weight bias)) (defun train-svm-sgd (training-data learning-rate regularization-parameter) (let ((weight (make-dvec (length (cdar training-data)) 0d0)) (bias 0d0) (v-scale-result (make-dvec (length (cdar training-data)) 0d0))) (train-svm-sgd-all training-data weight bias learning-rate regularization-parameter v-scale-result)))
データを用意して実験
ここまでで訓練、予測、テストができたので、libsvmのサイトからデータセットを取ってきて試してみる。
$ wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/a1a $ wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/a1a.t $ wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/a9a $ wget http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/a9a.t
a1aは123次元、訓練データ1605個、a9aは123次元、訓練データ32,561個で、a9aの方はSVMで訓練させようとすると結構時間がかかる。これを読み込んで、教師信号と入力ベクトルのドット対のリストにする関数read-libsvm-dataを定義する。
(defun read-libsvm-data (data-path data-dimension) (let ((data-list nil)) (with-open-file (f data-path :direction :input) (labels ((read-loop (data-list) (let ((read-data (read-line f nil nil))) (if (null read-data) (nreverse data-list) (let* ((dv (make-array data-dimension :element-type 'double-float :initial-element 0d0)) (d (ppcre:split "\\s+" read-data)) (index-num-alist (mapcar (lambda (index-num-pair-str) (let ((index-num-pair (ppcre:split #\: index-num-pair-str))) (list (parse-integer (car index-num-pair)) (coerce (parse-number:parse-number (cadr index-num-pair)) 'double-float)))) (cdr d))) (training-label (coerce (parse-integer (car d)) 'double-float))) (dolist (index-num-pair index-num-alist) (setf (aref dv (1- (car index-num-pair))) (cadr index-num-pair))) (read-loop (cons (cons training-label dv) data-list))))))) (read-loop data-list))))) (defparameter a1a-train (read-libsvm-data "/path//to/a1a" 123)) (defparameter a1a-test (read-libsvm-data "/path//to/a1a.t" 123)) (defparameter a9a-train (read-libsvm-data "/path//to/a9a" 123)) (defparameter a9a-test (read-libsvm-data "/path//to/a9a.t" 123))
;;;;; a1aに対する訓練とテスト ;; パーセプトロン (multiple-value-bind (weight bias) (train-perceptron a1a-train) (test a1a-test weight bias)) ; Accuracy: 81.806435%, Correct: 25324, Total: 30956 ;; 線形SVM+SGD (let ((learning-rate 0.01d0) (regularization-parameter 0.01d0)) (multiple-value-bind (weight bias) (train-svm-sgd a1a-train learning-rate regularization-parameter) (test a1a-test weight bias))) ; Accuracy: 83.09859%, Correct: 25724, Total: 30956 ;;;;; a9aに対する訓練とテスト ;; パーセプトロン (multiple-value-bind (weight bias) (train-perceptron a9a-train) (test a9a-test weight bias)) ; Accuracy: 79.988945%, Correct: 13023, Total: 16281 ;; 線形SVM+SGD (let ((learning-rate 0.01d0) (regularization-parameter 0.001d0)) (multiple-value-bind (weight bias) (train-svm-sgd a9a-train learning-rate regularization-parameter) (test a9a-test weight bias))) ; Accuracy: 84.601685%, Correct: 13774, Total: 16281
となって、このデータでは線形SVMも通常のSVMとほぼ同等の性能を出すことが分かった。
訓練時間を比較してみると、
;;; パーセプトロン (time (train-perceptron a1a-train)) ; Evaluation took: ; 0.002 seconds of real time ; 0.002046 seconds of total run time (0.002046 user, 0.000000 system) ; 100.00% CPU ; 4,414,171 processor cycles ; 131,072 bytes consed (time (train-perceptron a9a-train)) ; Evaluation took: ; 0.011 seconds of real time ; 0.011445 seconds of total run time (0.011445 user, 0.000000 system) ; 100.00% CPU ; 26,044,485 processor cycles ; 2,850,816 bytes consed ;;; 線形SVM (time (let ((learning-rate 0.01d0) (regularization-parameter 0.01d0)) (train-svm-sgd a1a-train learning-rate regularization-parameter))) ; Evaluation took: ; 0.004 seconds of real time ; 0.004468 seconds of total run time (0.004468 user, 0.000000 system) ; 100.00% CPU ; 9,648,051 processor cycles ; 393,216 bytes consed (time (let ((learning-rate 0.01d0) (regularization-parameter 0.001d0)) (train-svm-sgd a9a-train learning-rate regularization-parameter))) ; Evaluation took: ; 0.023 seconds of real time ; 0.023348 seconds of total run time (0.023348 user, 0.000000 system) ; 100.00% CPU ; 53,203,526 processor cycles ; 8,192,000 bytes consed
となって、データ数に比例して計算時間が増えているのが分かる。SVMでは20秒くらいかかっていたのが一瞬で終わるのがすごい。これなら数GBクラスのデータセットでも扱えそうである。
今回はデータセットをリストで表現しているが、これが数GBクラスのサイズになってくるとメモリ上にとっておくのが大変になってくる。しかしオンライン学習ならデータをファイルから一つ一つ読み込みながら学習することもできるので、メモリ量による制約もほとんどない。低スペックな普通のPCでも本格的なビッグデータを解析できるという利点は大きい。
さらに高度な手法(AROW、SCW、ASGD)も今度暇なときにでも実装してみようと思う。
ClackのミドルウェアでOAuth認証: Twitterログインしてみる
Clackのチュートリアル を読んだところ、アプリケーション本体に前処理と後処理をかぶせるミドルウェアという仕組みがあるらしい。ミドルウェアにはセッション管理やロガーなどが用意されていて、自分で書くこともできる。
ミドルウェアの中に、CLACK.MIDDLEWARE.OAUTHというOAuth認証をやってくれるものを見つけたので早速試してみた。cl-oauthによるTwitterログインとsrc/contrib/middleware/oauth.lispを読み比べると、リクエストトークンの取得から認証ページへのジャンプ、コールバックの際のGETパラメータからアクセストークンオブジェクトを作るところまでミドルウェアがうまいこと隠してくれているのが分かる。
前準備として、Twitterのページでアプリを生成する。
- Twitterの開発者向けのページを開き、Create New Appを押す
- アプリの名前とかを入力。今回は "clack-oauth-test" とした。その後既約に同意して作成完了。Callback URLはリクエストトークンに入れて送るので本当はいらないけど、とりあえず何か入力しておかないとエラーになるので注意。
- 次に作成されたアプリの管理画面に入るので、API Keysタブを選択し、API keyとAPI secretをメモる。これがconsumer-keyとconsumer-secretとなる。
cl-oauthでAPIにリクエストを出すときにパラメータが入っているとエラーになるバグがあったので修正を送ってマージしてもらった。まだQuicklispに反映されてないので、githubにある最新版を入れる。
$ cd ~/quicklisp/local-projects/ $ git clone https://github.com/skypher/cl-oauth.git
次にQuicklispからClackとCLACK.MIDDLEWARE.OAUTHをインストール
(ql:quickload :clack) (ql:quickload :clack-middleware-oauth)
作業用のパッケージを作っておく
(defpackage :clack-oauth-test (:use :common-lisp :clack :clack.middleware.oauth)) (in-package :clack-oauth-test)
次に、アプリ本体の関数とコールバック関数を定義する。
コールバック関数はOAuth認証が成功した時に呼ばれる関数で、リクエストと取得したアクセストークンを引数に取り、本体の関数と同様の返り値を返す。とりあえずここではコールバック関数はアクセストークンを変数に保存するだけ。
(defun app (env) '(200 ; HTTPステータスコード (:content-type "text/plain") ; Content-type ("Hello, Clack!"))) ; 中身 (defvar *request*) (defvar *access-token*) ;; 認証成功時に呼ばれる関数 (defun callback (request access-token) (setf *request* request) (setf *access-token* access-token) '(200 (:content-type "text/plain") ("Authorized!")))
次に、アプリ本体の関数にミドルウェアをかぶせてサーバを起動する。
;; サーバを起動する (defparameter handler (clackup (wrap (make-instance '<clack-middleware-oauth> :consumer-key "xxxxxxxxxxxxxxxxxxxxxxxxx" :consumer-secret "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" :authorize-uri "https://api.twitter.com/oauth/authorize" :request-token-uri "https://api.twitter.com/oauth/request_token" :access-token-uri "https://api.twitter.com/oauth/access_token" :path "/auth" :callback-base "http://localhost:5000" :authorized #'callback) #'app))) ;; サーバを止める。app等を更新したときは、サーバを一旦止めて、再びclackupする ; (stop handler)
この状態で http://localhost:5000 にアクセスすると、app関数の"Hello, Clack!"が表示され、 http://localhost:5000/auth にアクセスするとTwitterの認証ページに飛ばされる。認証が完了するとhttp://localhost:5000/authに戻ってきて、"Authorized!"が表示される。
この時点で*access-token*に取得したアクセストークンが入っている。
CLACK-OAUTH-TEST> *access-token*
#<CL-OAUTH:ACCESS-TOKEN
:CONSUMER #<CL-OAUTH:CONSUMER-TOKEN
:KEY "xxxxxxxxxxxxxxxxxxxxxxxxxx"
:SECRET "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
:USER-DATA NIL
:LAST-TIMESTAMP 0>
:KEY "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
:SECRET "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
:USER-DATA (("user_id" . "49735943") ("screen_name" . "masatoi0"))
:SESSION-HANDLE NIL
:EXPIRES NIL
:AUTHORIZATION-EXPIRES NIL
:ORIGIN-URI "https://api.twitter.com/oauth/access_token">アクセストークンが取得できたので、APIからホームタイムラインやキーワード検索を引っ張ってこれるようになった。
(ql:quickload :cl-json) (ql:quickload :babel) (defun home-timeline (access-token &key (count 20) since-id max-id) (json:decode-json-from-string (babel:octets-to-string (oauth:access-protected-resource "https://api.twitter.com/1.1/statuses/home_timeline.json" access-token :user-parameters (remove-if #'null (list (cons "count" (format nil "~D" (truncate count))) (if since-id (cons "since_id" (format nil "~D" (truncate since-id)))) (if max-id (cons "max_id" (format nil "~D" (truncate max-id)))))))))) (defun search-twitter (access-token keyword &key (count 20) since-id max-id lang) (json:decode-json-from-string (babel:octets-to-string (oauth:access-protected-resource "https://api.twitter.com/1.1/search/tweets.json" access-token :user-parameters (remove-if #'null (list (cons "q" keyword) (cons "count" (format nil "~D" (truncate count))) ; (cons "result_type" "popular") ; "mixed" "recent" (if since-id (cons "since_id" (format nil "~D" (truncate since-id)))) (if max-id (cons "max_id" (format nil "~D" (truncate max-id)))) (if lang (cons "lang" lang)) ; ja や en など ))))))
REPLでhome-timelineを評価してみると
CLACK-OAUTH-TEST> (home-timeline *access-token*)
(((:CREATED--AT . "Thu Aug 28 08:53:36 +0000 2014") (:ID . 504914685481590786)
(:ID--STR . "504914685481590786")
(:TEXT . "ClackのミドルウェアでTwitterのOAuth認証してみる")
(:SOURCE
. "<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>")
(:TRUNCATED) (:IN--REPLY--TO--STATUS--ID) (:IN--REPLY--TO--STATUS--ID--STR)
(:IN--REPLY--TO--USER--ID) (:IN--REPLY--TO--USER--ID--STR)
(:IN--REPLY--TO--SCREEN--NAME)
(:USER (:ID . 49735943) (:ID--STR . "49735943") (:NAME . "Satoshi Imai")
(:SCREEN--NAME . "masatoi0") (:LOCATION . "Tokyo, Suginami")
(:DESCRIPTION
. "NAIST→マイクロ法人経営中。最近はFX/CFDトレードシステムを作ったりしてブラブラしてます。機械学習/AI/LISP/FreeBSD/Webプログラミング/金融工学")
(:URL . "http://t.co/PAlHGDEvXc")
(:ENTITIES
(:URL
(:URLS
((:URL . "http://t.co/PAlHGDEvXc")
(:EXPANDED--URL . "http://d.hatena.ne.jp/masatoi/")
(:DISPLAY--URL . "d.hatena.ne.jp/masatoi/") (:INDICES 0 22))))
(:DESCRIPTION (:URLS)))
(:PROTECTED) (:FOLLOWERS--COUNT . 192) (:FRIENDS--COUNT . 232)
(:LISTED--COUNT . 23) (:CREATED--AT . "Mon Jun 22 19:31:26 +0000 2009")
(:FAVOURITES--COUNT . 254) (:UTC--OFFSET . 32400) (:TIME--ZONE . "Tokyo")
(:GEO--ENABLED) (:VERIFIED) (:STATUSES--COUNT . 3082) (:LANG . "ja")
(:CONTRIBUTORS--ENABLED) (:IS--TRANSLATOR) (:IS--TRANSLATION--ENABLED)
(:PROFILE--BACKGROUND--COLOR . "D9D9D9")
(:PROFILE--BACKGROUND--IMAGE--URL
. "http://abs.twimg.com/images/themes/theme1/bg.png")
(:PROFILE--BACKGROUND--IMAGE--URL--HTTPS
. "https://abs.twimg.com/images/themes/theme1/bg.png")
(:PROFILE--BACKGROUND--TILE)
(:PROFILE--IMAGE--URL
. "http://pbs.twimg.com/profile_images/501986906893082625/kP1VOc48_normal.png")
(:PROFILE--IMAGE--URL--HTTPS
. "https://pbs.twimg.com/profile_images/501986906893082625/kP1VOc48_normal.png")
(:PROFILE--LINK--COLOR . "877E28")
(:PROFILE--SIDEBAR--BORDER--COLOR . "000000")
(:PROFILE--SIDEBAR--FILL--COLOR . "DCDEF5")
(:PROFILE--TEXT--COLOR . "333333") (:PROFILE--USE--BACKGROUND--IMAGE)
(:DEFAULT--PROFILE) (:DEFAULT--PROFILE--IMAGE) (:FOLLOWING)
(:FOLLOW--REQUEST--SENT) (:NOTIFICATIONS))
(:GEO) (:COORDINATES) (:PLACE) (:CONTRIBUTORS) (:RETWEET--COUNT . 0)
(:FAVORITE--COUNT . 0)
(:ENTITIES (:HASHTAGS) (:SYMBOLS) (:URLS) (:USER--MENTIONS)) (:FAVORITED)
(:RETWEETED) (:LANG . "ja"))
...
)とJSON形式をパースしたツイートのリストが手に入る。JSONデータを取得できたので、あとはTweetのクラスを定義したり、HTMLの形にゴリゴリ整形して表示させたりと色々なことができそうである。蛇足になるが一応載せておく
;;; ここからcl-whoを使ってHTMLを書くのでパッケージを再定義しておく (ql:quickload :cl-who) (defpackage :clack-oauth-test (:use :common-lisp :clack :clack.middleware.oauth :cl-who :anaphora :alexandria)) (defmacro html (&body body) (let ((s (gensym))) `(with-html-output-to-string (,s) ,@body))) (defmacro defclass$ (class-name superclass-list &body body) "Simplified definition of classes which similar to definition of structure. [Example] (defclass$ agent (superclass1 superclass2) currency (position-upper-bound 1)) ; specify init value => #<STANDARD-CLASS AGENT>" `(defclass ,class-name (,@superclass-list) ,(mapcar (lambda (slot) (let* ((slot-symbol (if (listp slot) (car slot) slot)) (slot-name (symbol-name slot-symbol)) (slot-initval (if (listp slot) (cadr slot) nil))) (list slot-symbol :accessor (intern (concatenate 'string slot-name "-OF")) :initarg (intern slot-name :KEYWORD) :initform slot-initval))) body))) (defclass$ tweet () json-data id retweet-user-name retweet-user-screen-name timestamp text user-name user-screen-name profile-image-url entities entities-urls entities-hashtags entities-user-mentions state-list) (defun parse-twitter-timestring (timestring) (let* ((three-char-month-list '("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")) (year (subseq timestring 26 30)) (month (format nil "~2,'0D" (1+ (position (subseq timestring 4 7) three-char-month-list :test #'string=)))) (day (subseq timestring 8 10)) (hour-min-sec (subseq timestring 11 19)) (timezone (subseq timestring 20 25))) (local-time:parse-timestring (concatenate 'string year "-" month "-" day "T" hour-min-sec timezone)))) (defun make-tweet (json-tweet) (let ((retweeted-status (cdr (assoc :RETWEETED--STATUS json-tweet))) (user (cdr (assoc :USER json-tweet)))) (if retweeted-status ;; retweet (let ((retweeted-user (cdr (assoc :USER retweeted-status)))) (make-instance 'tweet :json-data json-tweet :id (cdr (assoc :ID json-tweet)) :retweet-user-name (cdr (assoc :NAME user)) :retweet-user-screen-name (cdr (assoc :SCREEN--NAME user)) :timestamp (parse-twitter-timestring (cdr (assoc :CREATED--AT retweeted-status))) :text (cdr (assoc :TEXT retweeted-status)) :user-name (cdr (assoc :NAME retweeted-user)) :user-screen-name (cdr (assoc :SCREEN--NAME retweeted-user)) :profile-image-url (cdr (assoc :PROFILE--IMAGE--URL retweeted-user)) :entities (sort (apply #'append (mapcar #'cdr (cdr (assoc :entities retweeted-status)))) (lambda (a b) (> (cadr (assoc :indices a)) (cadr (assoc :indices b))))))) ;; normal (make-instance 'tweet :json-data json-tweet :id (cdr (assoc :ID json-tweet)) :retweet-user-name nil :retweet-user-screen-name nil :timestamp (parse-twitter-timestring (cdr (assoc :CREATED--AT json-tweet))) :text (cdr (assoc :TEXT json-tweet)) :user-name (cdr (assoc :NAME user)) :user-screen-name (cdr (assoc :SCREEN--NAME user)) :profile-image-url (cdr (assoc :PROFILE--IMAGE--URL user)) :entities (sort (apply #'append (mapcar #'cdr (cdr (assoc :entities json-tweet)))) (lambda (a b) (> (cadr (assoc :indices a)) (cadr (assoc :indices b))))))))) ;; URLやID、ハッシュタグにリンクを付けたものを返す (defun add-link-to-text (text entities) (reduce (lambda (text alist) (let ((indices (aif (assoc :indices alist) (cdr it))) (url (aif (assoc :url alist) (cdr it))) (display-url (aif (assoc :display--url alist) (cdr it))) (hashtag-text (aif (assoc :text alist) (cdr it))) (screen-name (aif (assoc :screen--name alist) (cdr it)))) (cond (url (concatenate 'string (subseq text 0 (car indices)) "<a href=\"" url "\" target=\"_blank\"\">" display-url "</a>" (subseq text (cadr indices)))) (hashtag-text (concatenate 'string (subseq text 0 (car indices)) "<a href=\"https://twitter.com/search?q=" (hunchentoot:url-encode hashtag-text) "&src=hash\" target=\"_blank\"\">#" hashtag-text "</a>" (subseq text (cadr indices)))) (screen-name (concatenate 'string (subseq text 0 (car indices)) "<a href=\"https://twitter.com/" screen-name "\" target=\"_blank\"\">@" screen-name "</a>" (subseq text (cadr indices)))) (t text)))) entities :initial-value text)) (defun render-tweet (tweet) (html (:div :class "tweet-body" (:div :class "tweet-icon" (:img :src (profile-image-url-of tweet) :align "left")) (:div :class "tweet-id" (:a :href (concatenate 'string "https://twitter.com/" (user-screen-name-of tweet)) :target "_blank" (:strong (str (user-name-of tweet)))) (str (concatenate 'string " @" (user-screen-name-of tweet)))) (aif (retweet-user-name-of tweet) (htm (:a :class "retweeted-by" :href (concatenate 'string "https://twitter.com/" (retweet-user-screen-name-of tweet)) :target "_blank" (str (concatenate 'string " retweeted by " it))))) (:div :class "tweet-text" (str (add-link-to-text (text-of tweet) (entities-of tweet)))) (:a :class "tweet-timestamp" :href (concatenate 'string "https://twitter.com/" (user-screen-name-of tweet) "/status/" (format nil "~A" (id-of tweet))) :target "_blank" (str (local-time:format-timestring nil (timestamp-of tweet) :format local-time:+rfc-1123-format+))) ;; (:p (str (local-time:format-rfc1123-timestring nil (local-time:now)))) ; debug ))) (defparameter stylesheet ".tweet-body{ border: 1px solid #333; border-radius: 10px; color: #333333; width: 525px; padding: 0.4em; float: left; margin: 3px 0px 0px 0px; } .tweet-id{ width: 265px; float: left; } .retweeted-by{ color: #888888; font-size:84%; width: 210px; float: left; text-align: right; } .tweet-text{ color: #333333; width: 475px; float: left; } .tweet-timestamp{ color: #888888; font-size:84%; width: 525px; float: left; text-align: right; }") (defun callback (request access-token) (setf *request* request) (setf *access-token* access-token) `(200 (:content-type "text/html") (,(html (:html (:head (:style :type "text/css" (str stylesheet))) (:body (:p "Authorized!") (str (reduce (lambda (t1 t2) (concatenate 'string t1 t2)) (mapcar (lambda (json-tweet) (render-tweet (make-tweet json-tweet))) (home-timeline access-token))))))))))

Xmodmapとのどか(旧窓使いの憂鬱)の設定ファイルを晒してみる
- HHKが前提だけど日本語キーボードでも一応使えると思う
- 新たな修飾キーModeSwitchを入れることで、ホームポジション周辺3列にできるだけ全てのキーを詰め込もうとしている
- SKK使いなので小指の負担を減らすために右手のShiftはホームポジションの小指の位置に。そもそもコロンやセミコロンはそれほど多用するキーではないのに何故ホームポジションにあるのか謎である。
- Lisperが特に多用する括弧はModeSwitchとの組合せでSとDの位置に割り当てる
- 数字もModeSwitchとの組合せでテンキーっぽく配列
- 左利きなのでModeSwitchを右手に割り当てて、左手を動かすようになっている

上の配列を実現するには、 ~/.Xmodmap に次のように書けばいい。
! <注意> ! modifiers のキーリピートを解除しておかないとsynergyとかでおかしなことになる. ! $ xset -r [keycode] ! で解除できる. ! ! $XFree86: xc/programs/Xserver/hw/xfree86/etc/xmodmap.std,v 3.5 1996/12/23 06:47:28 dawes Exp $ ! ! Standard key mapping for XFree86 (for US keyboards). ! ! This file can be fed to xmodmap to restore the default mapping. ! ! $XConsortium: xmodmap.std /main/7 1996/02/21 17:48:55 kaleb $ ! ! First, clear the modifiers ! clear shift clear lock clear control clear mod1 clear mod2 clear mod3 clear mod4 clear mod5 ! ! Set the mapping for each key ! keycode 8 = keycode 9 = grave asciitilde keycode 10 = 1 exclam keycode 11 = 2 at keycode 12 = 3 numbersign keycode 13 = 4 dollar keycode 14 = 5 percent keycode 15 = 6 asciicircum keycode 16 = 7 ampersand keycode 17 = 8 asterisk keycode 18 = 9 parenleft keycode 19 = 0 parenright keycode 20 = minus underscore keycode 21 = equal plus keycode 22 = BackSpace keycode 23 = Tab keycode 24 = q Q 1 keycode 25 = w W 2 keycode 26 = e E 3 keycode 27 = r R 4 keycode 28 = t T 5 keycode 29 = y Y keycode 30 = u U keycode 31 = i I semicolon colon keycode 32 = o O 0 keycode 33 = p P keycode 34 = minus underscore keycode 35 = backslash bar keycode 36 = Return keycode 37 = Control_L keycode 38 = a A question keycode 39 = s S parenleft percent bracketleft keycode 40 = d D parenright dollar bracketright keycode 41 = f F bracketleft braceleft keycode 42 = g G bracketright braceright keycode 43 = h H exclam exclam keycode 44 = j J Escape keycode 45 = k K plus asterisk keycode 46 = l L ampersand asciicircum keycode 47 = Shift_R Shift_R dollar keycode 48 = apostrophe quotedbl keycode 49 = Escape keycode 50 = Shift_L keycode 51 = backslash bar keycode 52 = z Z 6 keycode 53 = x X 7 keycode 54 = c C 8 keycode 55 = v V 9 keycode 56 = b B equal exclam keycode 57 = n N slash backslash keycode 58 = m M minus underscore keycode 59 = comma less grave asciitilde keycode 60 = period greater keycode 61 = Mode_switch keycode 62 = Alt_R keycode 63 = KP_Multiply keycode 64 = Meta_L keycode 65 = space keycode 66 = Control_L keycode 67 = F1 keycode 68 = F2 keycode 69 = F3 keycode 70 = F4 keycode 71 = F5 keycode 72 = F6 keycode 73 = F7 keycode 74 = F8 keycode 75 = F9 keycode 76 = F10 keycode 77 = Num_Lock keycode 78 = Multi_key keycode 79 = KP_Home KP_7 keycode 80 = KP_Up KP_8 keycode 81 = KP_Prior KP_9 keycode 82 = KP_Subtract keycode 83 = KP_Left KP_4 keycode 84 = NoSymbol KP_5 keycode 85 = KP_Right KP_6 keycode 86 = KP_Add keycode 87 = KP_End KP_1 keycode 88 = KP_Down KP_2 keycode 89 = KP_Next KP_3 keycode 90 = KP_Insert KP_0 keycode 91 = KP_Delete KP_Decimal !keycode 92 = X386Sys_Req keycode 93 = keycode 94 = keycode 95 = F11 keycode 96 = F12 ! keycodes 97-107 are not available on 84-key keyboards keycode 97 = Home keycode 98 = Up keycode 99 = Prior keycode 100 = Num_Lock keycode 101 = Begin keycode 102 = Alt_L keycode 103 = End keycode 104 = Down keycode 105 = Next keycode 106 = Insert keycode 107 = Delete keycode 108 = Control_R keycode 110 = Pause keycode 111 = Up keycode 112 = Prior keycode 113 = Left keycode 114 = Right ! keycodes 115-117 are only available on some extended keyboards ! (e.g., Microsoft's ergonomic keyboard). keycode 115 = Meta_L keycode 116 = Down keycode 117 = Next keycode 120 = Control_R keycode 129 = Meta_R keycode 131 = Alt_L keycode 208 = Control_R ! ! Set the modifiers add shift = Shift_L Shift_R add lock = Caps_Lock add control = Control_L Control_R add mod1 = Alt_L Alt_R ! If you have ServerNumlock set in your XF86Config, you can comment out !add mod2 = Numlock ! ! ! ! If you use any of the special default key mappings in Xconfig, they should be ! duplicated in this file. Mappings should be added before the section above ! which sets the modifiers. ! ! For the key specs: ! LeftAlt => keycode 64 ! RightAlt => keycode 113 ! AltGr => keycode 113 ! ScrollLock => keycode 78 ! RightCtl => keycode 109 ! ! For the mappings: ! Meta => Alt_L Meta_L ! Alt_R Meta_R ! Compose => Multi_key ! ModeShift => Mode_switch ! ModeLock => Mode_switch X386Mode_Lock ! ScrollLock => Scroll_Lock ! Control => Control_R ! ! If you use ModeShift or ModeLock, the following modifier must be set: ! add mod4 = Meta_L Meta_R add mod5 = Mode_switch ! ! For example, to get the equivalent of: ! ! ScrollLock ModeLock ! RightAlt ModeShift ! LeftAlt Meta ! RightCtl Compose ! ! use the following: ! !keycode 78 = Mode_switch X386Mode_Lock !keycode 113 = Mode_switch !keycode 64 = Alt_L Meta_L !keycode 109 = Multi_key ! !add mod5 = Mode_Switch ! When using ServerNumLock in your XF86Config, the following codes/symbols ! are available in place of 79-81, 83-85, 87-91 !keycode 136 = KP_7 !keycode 137 = KP_8 !keycode 138 = KP_9 !keycode 139 = KP_4 !keycode 140 = KP_5 !keycode 141 = KP_6 !keycode 142 = KP_1 keycode 143 = Meta_L !keycode 144 = KP_3 !keycode 145 = KP_0 !keycode 146 = KP_Decimal !keycode 147 = Home !keycode 148 = Up !keycode 149 = Prior !keycode 150 = Left !keycode 151 = Begin !keycode 152 = Right !keycode 153 = End !keycode 154 = Down !keycode 155 = Next !keycode 156 = Insert !keycode 157 = Delete !マウスの左と右を入れ替える !pointer = 3 2 1 5 6 7 8 4 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ! for Expert Mouse 7.0 pointer = 3 2 1 5 4 6 7 8 9 10 11 12
のどか(旧窓使いの憂鬱)の場合
Windowsの場合はのどか(旧窓使いの憂鬱)によって同じ配列を実現できる。
104配列を指定した上で、以下の内容のファイルを読み込む
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Nodoka - dotjp.nodoka
# Copyright (C) 1999-2005, TAGA Nayuta <nayuta@users.sourceforge.net>
#
# Modify by applet on 2010-03-29
# まずキーボード定義を読み込む。
if ( USE104 )
include "104.nodoka" # 104 キーボード設定
if ( USE109on104 )
include "109on104.nodoka" # 104 キーボードを 109 キーボード風に
endif
else
include "109.nodoka" # 109 キーボード設定
if ( USE104on109 )
include "104on109.nodoka" # 109 キーボードを 104 キーボード風に
endif
endif
if ( USEdefault )
include "default2.nodoka" # Emacs ライクなさまざまな設定
endif
# Global keymap 設定
keymap Global
# 以下は、便宜上、設定するもの
key C-A-D = &DescribeBindings # 現在のキーマップのログ出力
key F1 = &SendPostMessage("PostTray",,"のどか", 0x0205, 0, 0) # のどかのメニューを開く
# シフト+F2: 日本語キーボード、英語キーボード 切り替えトグル
if ( USE109 )
if ( USE104on109 )
key S-F2 => &IconColor(0) &HelpMessage("Reloaded", "日本語 109 キーボード") &LoadSetting("日本語 109 キーボード")
else
key S-F2 => &IconColor(2) &HelpMessage("Reloaded", "日本語 109 キーボード (104 風)") &LoadSetting("日本語 109 キーボード (104 風)")
endif
endif
if ( USE104 )
if ( USE109on104 )
key S-F2 => &IconColor(0) &HelpMessage("Reloaded", "英語 104 キーボード") &LoadSetting("英語 104 キーボード")
else
key S-F2 => &IconColor(2) &HelpMessage("Reloaded", "英語 104 キーボード (109 風)") &LoadSetting("英語 104 キーボード (109 風)")
endif
endif
# 以下に、ご自身の設定を御書き下さい。
#HHK固有設定
def key LeftDiamond = 0x7b
def key RightDiamond = 0x79
keymap Global
#以降の設定をIMEの未確定入力時にも適用
key *IC- =
#Slashをモディファイヤキーとする入力
mod mod0 = !Slash
key M0-A = S-Slash # ?
key M0-S = S-_9 # (
key M0-D = S-_0 # )
key M0-B = Equal # =
key M0-F = LeftSquareBracket #[
key M0-S-F = S-LeftSquareBracket #{
key M0-G = RightSquareBracket #]
key M0-S-G = S-RightSquareBracket #}
key M0-N = Slash #/
key M0-S-N = BackSlash #\
key M0-Comma = GraveAccent #`
key M0-S-Comma = S-GraveAccent #~
key M0-Q = _1 # 1
key M0-W = _2 # 2
key M0-E = _3 # 3
key M0-R = _4 # 4
key M0-T = _5 # 5
key M0-Z = _6 # 6
key M0-X = _7 # 7
key M0-C = _8 # 8
key M0-V = _9 # 9
key M0-O = _0 # 0
key M0-L = S-_7 # &
key M0-S-L = S-_6 # ^
key M0-K = S-Equal # +
key M0-S-K = S-_8 # *
key M0-M = Minus # -
key M0-S-M = S-Minus # _
key M0-N = Slash # /
key M0-S-N = BackSlash # \
key M0-I = Semicolon # ;
key M0-S-I = S-Semicolon # :
key M0-J = BS
key M0-S-B = S-_1
key LeftSquareBracket = Minus
key S-LeftSquareBracket = S-Minus
key RightSquareBracket = BackSlash
key S-RightSquareBracket = S-BackSlash
# EscapeとGraveAccentの交換
key Esc = GraveAccent
key GraveAccent = Esc
mod shift += !Semicolon
mod alt -= !RightAlt
mod control += !RightAlt
clml-svmの紹介
この記事ではclml-svmを紹介する。SVMそのものの解説はしない。
CLML (Common Lisp Machine Learning)は、数理システムからgithubに公開されているCommon Lisp用の機械学習ライブラリである。以前は売り物であったらしい。当初はライセンスが不明だったがこのほどLLGPLで公開されることが明記されたので安心して使うことができる。しかしCLMLはASDFでシステム定義されておらず、そのままではSBCLなどでうまくコンパイルできない。また依存ライブラリやサンプルデータを全部詰め込んで配布されているため282MBもある。依存ライブラリはQuicklispから入るようなものばかりなので除くことができる。あとはASDFのシステム定義ファイルを書く必要がある。
とりあえず自分がよく使うソフトマージンSVMをCLMLから単離して、もっと簡単にインストールできる形にしてgithubに置くことにした。とりあえずSBCLとCCLで動作確認した。ついでにデータのスケーリングやクロスバリデーションの結果に基づくメタパラメータ探索をつけた。SVMの性能はこういうチューニングにかなり左右される。SVMの利用についてはこのスライドが分かりやすい。
Common LispでSVMを使うときのもう一つの選択肢としては、libsvmのラッパーライブラリであるcl-libsvmがあるが、しばらく更新されていない模様。clml-svmのアルゴリズムはlibsvmと同じ種類のSMOであり、訓練にかかる時間もlibsvmと大差ない。アルゴリズムの詳細はこちらの論文(PDF)にある。
インストール
$ cd ~/quicklisp/local-projects/ $ git clone https://github.com/masatoi/clml-svm.git
(ql:quickload "clml-svm")
データを用意する
個々のデータ点は要素の型がdouble-floatの配列で、データ点の内容に加え、最後の要素に学習ラベル(-1d0か1d0)が入っている。そして訓練データセットはデータ点からなる単純配列である。
例えば4つのデータ点を持つ入力が2次元の排他的論理和のデータ(図3.3)なら次のようになる。
(defparameter exor-vector (make-array 4 :initial-contents (list (make-array 3 :element-type 'double-float :initial-contents '(0d0 0d0 -1d0)) (make-array 3 :element-type 'double-float :initial-contents '(1d0 0d0 1d0)) (make-array 3 :element-type 'double-float :initial-contents '(0d0 1d0 1d0)) (make-array 3 :element-type 'double-float :initial-contents '(1d0 1d0 -1d0))))) #(#(0.0d0 0.0d0 -1.0d0) #(1.0d0 0.0d0 1.0d0) #(0.0d0 1.0d0 1.0d0) #(1.0d0 1.0d0 -1.0d0))
ファイルから読み込む
関数read-libsvm-data-from-fileを使ってlibsvmのデータセットの形式のファイルを読み込むことができる。これは各データ点の要素のうちゼロでないものだけをインデックスを付けて記述する形式で、データがスパースであれば容量の節約になる。
例としてa1aデータの訓練データとテストデータをダウンロードして読み込んでみよう。
(defparameter training-vector (svm:read-libsvm-data-from-file "/path/to/datasets/a1a")) (defparameter test-vector (svm:read-libsvm-data-from-file "/path/to/datasets/a1a.t"))
SVMモデルをつくる(訓練する)
まずカーネル関数を決める必要がある。カーネル関数は線形カーネルとRBFカーネルと多項式カーネルが用意されており、自分で定義することもできるが、基本的にはRBFカーネルでいいらしい。RBFカーネルは釣鐘状の関数だが、その広がりを表すパラメータgammaを指定してやる必要がある。
次に、関数make-svm-modelに訓練データとカーネル関数、マージンを侵す場合の罰則パラメータCを与えて、訓練されたモデルをつくる。
(defparameter kernel (svm:make-rbf-kernel :gamma 0.03125d0)) (defparameter model (svm:make-svm-model training-vector kernel :C 4.0d0))
ここで2つのメタパラメータgammaとCが出てきたが、その値をどのように決めればいいのかは探索してみるしかない。これついては後述する。
訓練したモデルから未知のデータを予測する
次に、判別関数discriminateを使って未知のデータ点を予測する。試しにテストデータの最初のデータ点を予測してみる。(aref test-vector 0)の最後の要素は-1.0d0なのでこれは外れ。
テストデータ全体で予測と実際の値を比べるにはsvm-validationを使う。この関数は予測の内訳と正答率を多値で返す。例えば、最初の返値のリストのcarは、本当は-1.0d0のものを1.0d0と予測した回数が3062回であることを表している。ここから感度や特異度を計算できる。2つ目の返値の正答率は84.4%となった。
(svm:discriminate model (aref test-vector 0)) ; => 1.0d0 (svm:svm-validation model test-vector) ; => (((-1.0d0 . 1.0d0) . 3062) ((1.0d0 . 1.0d0) . 4384) ((-1.0d0 . -1.0d0) . 21742) ((1.0d0 . -1.0d0) . 1768)), ; 84.39720894172373d0
クロスバリデーション
上の例では訓練データとテストデータを別々に用意していたが、一つのデータセットの一部をテストデータとして使い、残りの部分を訓練データとする方法があり、クロスバリデーションと呼ばれる。clml-svmでは、データをN分割して、1個をテストデータとして使い、残りのN-1個を訓練データとして学習することをN回繰り返す(N分割クロスバリデーション)。
関数cross-validationはデータの分割数と、make-svm-modelと同様の引数を取り、N回の正答率の平均と、その内訳を返す。
(svm:cross-validation 5 training-vector kernel :C 4.0d0) ; => 83.17757009345794d0, ; (83.8006230529595d0 78.50467289719626d0 84.42367601246106d0 85.66978193146417d0 83.48909657320873d0)
メタパラメータ探索
ここまでgammaやCといったメタパラメータの値は適当に設定してきたが、グリッドサーチでこれらの値を調べることもできる。ただしとても時間がかかるので、データセットのサイズを調整するなどした方がいい。
関数grid-searchは訓練データとテストデータのみを取り、最も良かった正答率と、そのときのgammaとCの組合せを返す。
(svm:grid-search training-vector test-vector) ; => 84.413360899341d0, 正答率 ; 0.0078125d0, gamma ; 8.0d0 C
また、標準出力には全てのgammaとCの組み合わせの正答率と所要時間が表示される。(追記:gammaとCじゃなくてlog2(gamma)とlog2(C)だった)
# gamma C accuracy time 3.0 -5.0 75.94650471637162 6.921 1.0 -5.0 75.94650471637162 6.937 -1.0 -5.0 75.94650471637162 6.383 -3.0 -5.0 75.94650471637162 3.79 -5.0 -5.0 75.94650471637162 3.686 -7.0 -5.0 75.94650471637162 3.638 -9.0 -5.0 75.94650471637162 3.617 -11.0 -5.0 82.78524357152087 3.598 -13.0 -5.0 82.89184649179481 3.64 -15.0 -5.0 82.93707197312314 3.582 ・・・中略・・・ 3.0 15.0 76.10156350949735 7.04 1.0 15.0 76.10156350949735 7.038 -1.0 15.0 80.87931257268382 6.596 -3.0 15.0 80.92776844553559 3.763 -5.0 15.0 78.7246414265409 4.03 -7.0 15.0 77.82336219149761 10.689 -9.0 15.0 79.43532756170048 13.031 -11.0 15.0 83.4248610931645 6.994 -13.0 15.0 83.76405220312702 3.973 -15.0 15.0 83.79958650988499 3.149
これらはGnuplotの入力になっているので、ファイルに保存してgnuplotのsplotコマンドでプロットすることもできる。この場合、このような図になる。

モデルの評価のためにテストデータではなく、クロスバリデーションを使う場合は関数grid-search-by-cvを使う。
(svm:grid-search-by-cv 5 training-vector) ; => 83.55140186915887d0 ; 3.0517578125d-5 ; 512.0d0
データのスケーリング
a1aデータは入力の各次元が0と1のどちらかになっているバイナリデータだったが、一般には入力の各次元は数値である。そういう場合はデータ全体で各次元の数値が[-1,+1]に収まるようなスケーリングをすると性能が良くなるらしい。
スケーリングには関数autoscaleを使う。autoscaleはスケーリングされたデータセットとスケーリングパラメータの2つを返す。スケーリングされたデータで訓練したSVMを評価するときには、訓練データをスケーリングしたときのスケーリングパラメータをキーワード引数に指定してテストデータをautoscaleしなければならないことに注意が必要だ。
(multiple-value-bind (scaled-data scaling-params) (svm:autoscale training-vector) (defparameter training-vector.scaled scaled-data) (defparameter training-vector.scale-params scaling-params)) ;; TODO これが失敗する。training-vectorとtest-vectorの入力次元数が違っている(!)。 read-libsvm-data-from-fileのバグ (defparameter test-vector.scaled (svm:autoscale test-vector :scale-parameters training-vector.scale-params))
Lispbox for Windowsバイナリ配布
2016/1/21追記:最新版を公開しました http://d.hatena.ne.jp/masatoi/20160121/1453379153
Windows版のLispboxが色々古くなってたので更新したものを公開します。
内容は以下の通り。
- emacs 24.3
- slime 2014-1-10
- ccl 1.9
- quicklisp 2014-1-30
CCLとの通信はUTF-8で行うように設定済みなので日本語も通るはずです。
ダウンロード先
lispbox_windows_x86.zip
サイズがでかい(103MB)のでGoogle Driveに置いてみた。EmacsもでかいがCCLのコアイメージもでかい。CCLは32bit版と64bit版が両方入っていて、起動時にどちらかを自動的に選択するようになっている(lispbox-register.el)
今後更新するときに編集するべきポイント
- lispbox.bat中のEMACS変数に新しいEmacsへのパスを設定する
- 新しいEmacsのsite-lispフォルダに古いEmacsのsite-lispフォルダからlispbox.elをコピーする。Emacsは初期化ファイルなしで起動されているので、elispを書きたかったらこのファイルに書く。新しいLisp処理系とSLIMEへのパスをlispbox.elに設定する。
- 古いLisp処理系のフォルダ内のlispbox-register.elを新しいLisp処理系のフォルダへコピーする。lispbox.elはlispboxフォルダ内でlispbox-register.elを持つフォルダを探すことによって使うLisp処理系を特定するため、古いLisp処理系のフォルダのlispbox-register.elは名前を変えるか削除する必要がある。
- lispbox-register.elではQuicklispのsetup.lispを処理系起動時に読み込むように起動オプションを指定している。処理系の起動オプションをいじるならここで。
プログラム=データ=遺伝子? Lispは無慈悲な言語の女王
(Lisp Advent Calendar 2013 18日目の記事)
しばしばLispの特徴として「プログラムを生成するプログラムを書ける」ということが言われるわけだが、普通の人はこれを聞いてどう解釈したらよいものか悩むと思う。字面通りに受け取ると、あたかも勝手に世の中の問題を把握してそれを解決するプログラムを出力してくれる真の人工知能のようなものを想像してしまうかもしれない。しかし残念ながら、そうした所謂「強いAI」は人工知能研究における聖杯であり、いまだにSFの範疇から出るものではない。
LISPerの言う「プログラムを生成するプログラム」とは普通もっと限定された意味である。そしてそれはほとんどの場合マクロによって実現される。
evalとマクロ
Lispではプログラムとデータが同じ形をしているので、それまでプログラムとして扱っていたものを突如データとみなして操作することができる。逆に、データとして操作したコードはevalを使えば今度はプログラムとして評価されることになる。例えば、変数にnilを代入するnilfを二つの方法で定義してみる。
(defun nilf-1 (x) (eval (list 'setf x nil))) (defmacro nilf-2 (x) `(setf ,x nil)) (defparameter x 10) (nilf-1 'x) ;; x => nil (defparameter x 10) (nilf-2 x) ;; x => nil
nilf-1は関数の中でLispプログラムを組立て、それをevalで評価することによって関数の外の変数への代入を実現している。しかしnilf-1は関数であるため引数が評価されないようにクォートを付けて呼び出す必要がある。一方でマクロとして定義したnilf-2はクォートがいらない。
なぜこのような違いが生まれるのだろうか。それは評価されるタイミングが違うからである。
Common Lispではプログラムは読み込み時、コンパイル時、実行時の3つの段階を経て実行される。Lispプログラムを読み込むタイミングで展開されるのがクォートなどのリーダーマクロであり、コンパイル前に展開されるのが通常のマクロ、そして関数は実行時に評価される。ひとたびコンパイルされてしまえばそのプログラムを何回実行してもマクロ展開のオーバーヘッドは残らない。逆に、evalを使うやり方では実行時にその都度evalの評価対象のプログラムが組み立てられコンパイルされるため、効率上のデメリットがある。そのためevalはREPLを除けば普段はあまり目にすることはない。実際Clojurescriptのようにevalが封印されているものすらある。
ではevalを活用できる場面はないのかといえば、もちろんある。プログラムの実行時に新しいプログラムを生成するプログラムを書く必要があるときがそうだ。そのようなものとしては、例えば遺伝的プログラミングがある。
遺伝的プログラミングとは
遺伝的プログラミング(以下GP)とは遺伝的アルゴリズム(以下GA)の拡張の一つで、GAではビット列で遺伝子を表現するところを、GPでは木構造で遺伝子を表現するところが異なる。
ところでLispプログラムはS式で表現されているわけだが、S式は構文木そのものであるので、LispプログラムはそのままGPの遺伝子と見ることができる。この遺伝子=Lispプログラムの集団を交配によって徐々に変化させながら、各世代で生成されるLispプログラムを評価し、優良な個体を優先的に次世代に残すサイクルを繰り返すのがGPのアルゴリズムとなる。
交配の方法は色々あるが、代表的なものとしては突然変異(mutation)や交叉(crossover)がある。突然変異では一つの個体のノードが別のものに変わって新しい個体が生まれる。交叉では二つの個体が部分木を交換し、新しい個体が二つ生まれる。

ただし、交配の対象となる個体の選択や、これらの交配のための操作は確率的に行なわれるため、その確率を制御するためのメタパラメータを適当に設定してやる必要がある。
GPをLispで実装するのは他言語に比べれば非常に易しい。交配に伴なう操作は単なるリスト処理であり、個体であるLispプログラムを実行するには単にevalしてやればいいのだ。実際、遺伝的プログラミングの草分けとして知られるJohn R. Kozaの教科書のサンプルコードもCommon Lispで書かれている。
Kozaのプログラムの紹介
Kozaによるサンプルコードが以下のURLにあるのでダウンロードしてloadする。
http://faculty.hampshire.edu/lspector/courses/koza-gp.lisp
20年前のコードだが、CLtL2で書かれているので、後方互換性のあるANSI Common Lispに準拠した処理系ならそのまま動くはずだ(SBCL 1.1.7 on Linuxで動作確認済)。
(load "koza-gp.lisp")
今回は最も単純な例として回帰問題を扱う。まずデータセットを用意するところから始めよう。
(require :alexandria) ; 正規分布のサンプリングに使う ;; 近似対象の関数 (defun target-func (x) (* (- x 1) x (+ x 1))) (defparameter x-samples (loop repeat 100 collect (1- (random 2d0)))) (defparameter y-samples (mapcar (lambda (x) (+ (target-func x) (* (alexandria:gaussian-random) 0.1d0))) x-samples)) (defun define-fitness-cases () (mapcar #'list x-samples y-samples))
これで三次曲線(* (- x 1) x (+ x 1))の周りに分布するサンプル点が100個できる。このサンプル点の集合から元の関数を復元するのがこの問題の目的となる。
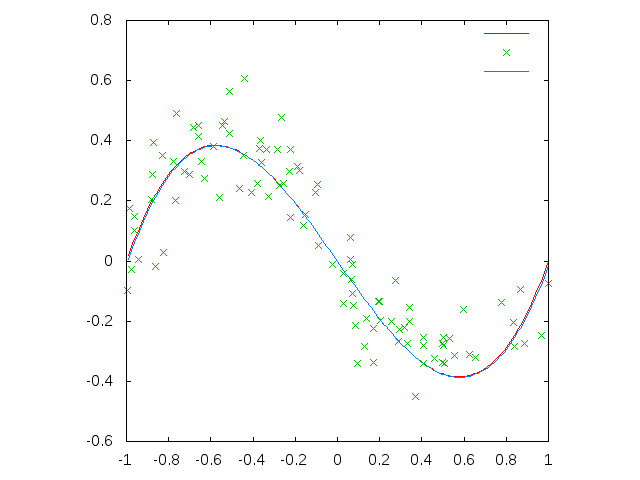
次に、個体=生成されるプログラムの素材として、どのような関数(非終端記号)や終端記号が使えるかを指定する必要がある。関数には任意のLisp関数が使えるが、引数の型チェックなどはしないようだ。今回は関数は四則演算のみ、終端記号としてはシンボルxとランダムの整数のみが使えるとする。
(defun define-terminal-set () (values '(x :integer-random-constant))) ;;; ゼロ除算でエラーを出さないように (defun % (numerator denominator) (if (= 0 denominator) 1 (/ numerator denominator))) (defun define-function-set () (values '(+ - * %) ; 候補の関数のリスト '(2 2 2 2))) ; それぞれの関数の引数の数
次にいよいよ評価関数を定義する。
評価関数は個体であるプログラムと、 define-fitness-cases で定義されるデータセットを受け取り、個体の評価値を返す。評価値は小さいほど良い。 program は (* (- x 1) x (+ x 1)) のようなリストなので、データセットのサンプル点の値をxに束縛して (eval program) することで予測値が出る。予測値と実際の値との平均二乗誤差(RMSE)を取って、これを評価値とする。
ついでに生成されるプログラムが巨大になるのを避けるために、木の深さに対する罰則項を付けておく。 *alpha* は誤差最小化とプログラムサイズ最小化のバランスを取るパラメータだ。
(defparameter *alpha* 0.001d0) (defun evaluate-fitness (program fitness-cases) (let* ((square-error (loop for data in fitness-cases sum (let* ((x (car data)) (y (cadr data)) (err (- (eval program) y))) (* err err)))) (rmse (sqrt (/ square-error (length fitness-cases))))) (+ rmse (* *alpha* (max-depth-of-tree program)))))
あとは諸々のパラメータや、終了条件を適当に設定し、これまで定義してきた関数をまとめて多値で返す問題関数REGRESSIONを定義する。
(defun define-parameters () (setf *max-depth-for-new-individuals* 5) (setf *max-depth-for-individuals-after-crossover* 10) (setf *fitness-proportionate-reproduction-fraction* 0.1) ; 一世代に交換される個体の割合 (setf *crossover-at-any-point-fraction* 0.2) (setf *crossover-at-function-point-fraction* 0.2) (setf *max-depth-for-new-subtrees-in-mutants* 4) (setf *method-of-selection* :fitness-proportionate) (setf *method-of-generation* :ramped-half-and-half) (values)) (defun define-termination-criterion (current-generation maximum-generations best-standardized-fitness best-hits) (declare (ignore best-standardized-fitness best-hits)) (values (>= current-generation maximum-generations))) ; 世代数が上限にいくまで ;;; 問題関数 (defun REGRESSION () (values 'define-function-set ; 関数名のシンボルのリストと各関数の引数の数のリストを返す関数 'define-terminal-set ; 終端記号のリストを返す関数 'define-fitness-cases ; 評価に使うデータセットを定義する関数 'evaluate-fitness ; 評価関数 'define-parameters ; 進化のメタパラメータを定義する関数 'define-termination-criterion)) ; 終了条件
以上で準備は終わりとなる。以下のようにしてシミュレーションを実行する。
(run-genetic-programming-system 'REGRESSION 1.0 ; 乱数のシード 100 ; 最大世代数 2000) ; 集団のサイズ
10分ほど待つと、以下のような結果が出力されていると思う。
Parameters used for this run. ============================= Maximum number of Generations: 100 Size of Population: 2000 Maximum depth of new individuals: 5 Maximum depth of new subtrees for mutants: 4 Maximum depth of individuals after crossover: 10 Fitness-proportionate reproduction fraction: 0.1 Crossover at any point fraction: 0.2 Crossover at function points fraction: 0.2 Number of fitness cases: NIL Selection method: FITNESS-PROPORTIONATE Generation method: RAMPED-HALF-AND-HALF Randomizer seed: 1.0d0 Generation 0: Average standardized-fitness = 682360.0034408907d0. The best individual program of the population had a standardized fitness measure of 0.18029786329188047d0 and NIL hits. It was: (% (- (% X -6) (- X 1)) (+ (* X -4) (% -1 X))) Generation 1: Average standardized-fitness = 30974.97849042459d0. The best individual program of the population had a standardized fitness measure of 0.18029786329188047d0 and NIL hits. It was: (% (- (% X -6) (- X 1)) (+ (* X -4) (% -1 X))) (中略) Generation 99: Average standardized-fitness = 264.06375933445685d0. The best individual program of the population had a standardized fitness measure of 0.14858744727766707d0 and NIL hits. It was: (% (* (* (* (+ -2 X) (+ -2 X)) (* (- -1 X) (% X -8))) (+ (* 8 (% 6 7)) (+ (- X -6) X))) -8) The best-of-run individual program for this run was found on generation 23 and had a standardized fitness measure of 0.11737380905714517d0 and NIL hits. It was: (* X (* X (+ X (% (+ (* (% X (+ -6 -7)) X) (% (- -4 (% X X)) X)) (- 6 1)))))
この最良の個体 (* X (* X (+ X (% (+ (* (% X (+ -6 -7)) X) (% (- -4 (% X X)) X)) (- 6 1))))) をプロットしたものが上の図の青線である。
赤線が元々の関数なのでほぼ正確に復元できていると思う。
第2章 Clojure ひとめぐり
2.1 フォーム
何がリテラルになるのかについての説明。有理数型が用意されていることなどCLとの重複は多い。
文字列はCLだと文字のベクタだったが、ClojureではJavaの文字列型を使っている。
;; Common Lisp (vectorp "hoge") ; T ;; Clojure (vector? "hoge") ; false
BigDecimal(任意精度の浮動小数点)とBigInt(任意精度の整数演算)もJavaの数値型をそのまま使う。リテラル表記はBigDecimalにはM、BigIntにはNを付ける。
(+ 1 (/ 0.00001M 1000000000000000000)) => 1.00000000000000000000001M (* 1000N 1000 1000 1000 1000 1000 1000) => 1000000000000000000000N
空リストが真。条件部が偽になるのはnilとfalseだけで、残りは全部真になる。
(if '() "True" "False") ; "True"
2.5 Javaを呼び出す
(def rnd (new java.util.Random)) ; => #'user/rnd
メソッド呼出しやフィールドへのアクセスは全部.(ドット)
;; 引数なしのメソッド呼出し (. rnd nextInt) ; => -1926271163 ;; 引数付きのメソッド呼出し (乱数の範囲を指定する) (. rnd nextInt 10) ; => 9 ;; フィールドへのアクセスも似たように書ける (. Math PI) ; => 3.141592653589793
毎回java.util.Randomと入力するのが面倒なら、useのようにimportを使うことで単にRandomと書ける。
(import '(java.util Random)) (def rnd2 (new Random)) ; => #'user/rnd2
2.6 フロー制御
CLのprognやSchemeのbeginに相当するのは do。CLのdoマクロとは全然違うので注意。
loop-recur構文はSchemeのnamed-letにちょっと似てる。
;; Clojure (defn my-reverse [lst] (loop [lst lst product '()] (if (empty? lst) product (recur (rest lst) (cons (first lst) product))))) ;; Scheme (define (my-reverse lst) (let loop ((lst lst) (product '())) (if (null? lst) product (loop (cdr lst) (cons (car lst) product)))))
ClojureのletはCL/Schemeでいうところのlet*と同等。局所変数束縛のところの括弧が少なくなってる。これだとちょっと見にくいのでカンマを入れたりする。Clojureではカンマは空白と同じらしい。じゃあ逆クオートに対するアンクオートはどうなるのかというと~(チルダ)を使う。
;; CL/Scheme (let* ((i 0) (j (+ i 1))) (print i) (print j)) ;; Clojure (let [i 0 , j (+ i 1)] (println i) (println j))
condもletと同じように括弧が少ないこと以外は同じ。デフォルト節の条件部に入れるものは真になるものならなんでもいい。今回は:elseとしておく。
(defn fizzbuzz [n] (loop [i 1] (if (<= i n) (do (cond (zero? (mod i 15)) (println "Fizz Buzz") (zero? (mod i 3)) (println "Fizz") (zero? (mod i 5)) (println "Buzz") :else (println i)) (recur (+ i 1))))))